2023. 9. 21. 14:02ㆍBlockchain/Roll up
Roll up Series
[Blockchain/Roll up] - Rollup의 개념과 특성
[Blockchain/Roll up] - ZK rollup - 1. 목적/library
[Blockchain/Roll up] - ZK rollup - 2. ZKP
[Blockchain/Roll up] - ZK rollup - 3. zkEVM 프로젝트
[Blockchain/Roll up] - ZK rollup - 4. zk-SNARK의 Circuit & QAP
ZK rollup은 블록체인, 특히 이더리움의 확장성을 증가시키기 위한 킬링 솔루션이다. 솔루션 구축의 난이도가 높은 것을 제외하면 다른 rollup 솔루션인 optimistic rollup과 비교하여, fraud proof 챌린지 존재로 인한 finality 기간 존재 및 높은 가스피 등의 이슈가 없기 때문에 많은 프로젝트들이 ZK rollup을 고도화 기술로 점 찍고 R&D를 하고 있다.
하지만 ZK rollup이 대중화 되는데 가장 큰 걸림돌이 있었으니, 바로 EVM과의 호환성 문제이다.
EVM 호환성
ZK rollup은 EVM과 호환되기 어려웠기 때문에 많은 ZK rollup 프로젝트들은 자신들의 특화 어플리케이션 기능에만 집중하여 개발되었다. 특히 토큰 같은 자산 교환에만 사용되었다. 그렇다면 왜 ZK rollup L2는 EVM을 적용시키기 힘들까? 당연하겠지만, 바로 EVM이 처음 설계될 당시 ZK rollup은 전혀 고려하지 않고 설계가 되었기 때문이다. 이더리움의 사용처가 늘어나고, 트랜잭션이 증가하면서 성능 향상에 대한 요구가 발생한 뒤에야 zk rollup 방식이 고려되었기 때문이다. 그 와중에 zk rollup에 많이 사용되는 zk-SNARK 구현 자체도 어려운데 이를 EVM에 적용 시키는 것도 힘든일이다.
그래서, zk rollup과 EVM의 호환을 위해 개발중인 zkEVM의 여러 프로젝트들을 확인해보고, 어떠한 방향으로 zk rollup 시 EVM을 구동(즉 솔리디티 컨트랙트를 실행 가능하도록)시킬 수 있는지 개념을 확인하려 한다.
zkEVM projects

EVM을 구현하는 방향에 따라 zkEVM 프로젝트들을 구분할 수 있다.
- EVM execution trace를 검증 가능한 circuit으로 변환하여 직접 증명
- 커스텀 VM을 생성하고 EVM opcode를 해당 VM의 opcode로 매핑한 다음, 해당 custom 환경에서 trace의 정확성을 증명
- 커스텀 VM을 생성하고 솔리디티를 custom VM의 바이트코드로 변환(직접 변환하거나 custom high level언어로)하고 custom 환경에서 증명
각각의 구현 방법에 따라 zkrollup 시에 EVM 동작에 대한 목표를 어떤식으로 달성할 수 있는지 확인해본다.
Option 1. Proving the EVM Execution Trace
위 그림의 4번째 Scroll과 ETH foundation의 Privacy Scaling Group이 함께 진행하는 Scroll이다. 그림을 보면 가장 우측의 이더리움의 EVM 동작 흐름과 일치함을 볼 수 있다. Scroll의 목표는 zk rollup을 사용하더라도 EVM과 똑같이 동작하도록 설계하는 것이며, 그에 따라 아래와 같은 설계가 필요하다.
- Circuit for some cryptographic accumulator
- Storage를 정확하게 읽고 올바른 바이트코드를 로드하는지 확인
- Circuit to linke the bytecode
- 바이트코드를 실제 동작 트레이스와 연결
- Circuit for each opcode
- 각 opcode에 대한 read/write 및 계산의 정확성 증명
Scroll의 구조와 롤업 방식에 대해 간략히 확인해본다.
Scroll architecture

3가지 레이어로 구분될 수 있다.
- Settlement layer
- L1(Ethereum) 상에 브리지 및 롤업 컨트랙트 배포 필요
- 데이터 가용성(Data availability) 및 sequence를 제공하고, 유효성 증명을 확인
- 사용자와 dAPP이 L1-L2간 메시지와 자산을 보낼 수 있도록 함
- Sequencing layer
- Scroll의 sequencer에 제출된 tx와 L1 브리지 컨트랙트에 제출된 tx를 실행
- L2 블록을 생성하는 실행 노드(execution node)와 tx batch 및 L1에 tx/블록 정보를 게시하는 롤업 노드로 구성
- 유효성 증명을 L1에 제출
- Proving layer
- 두개의 컴포넌트로 구성
- L2 tx의 정확성 검증 위한 zkEVM 유효성 증명 생성하는 provers
- 증명 작업(proving tasks)을 provers에 전달하고 유효성 증명을 롤업 노드로 전달하는 coordinator
Rollup process
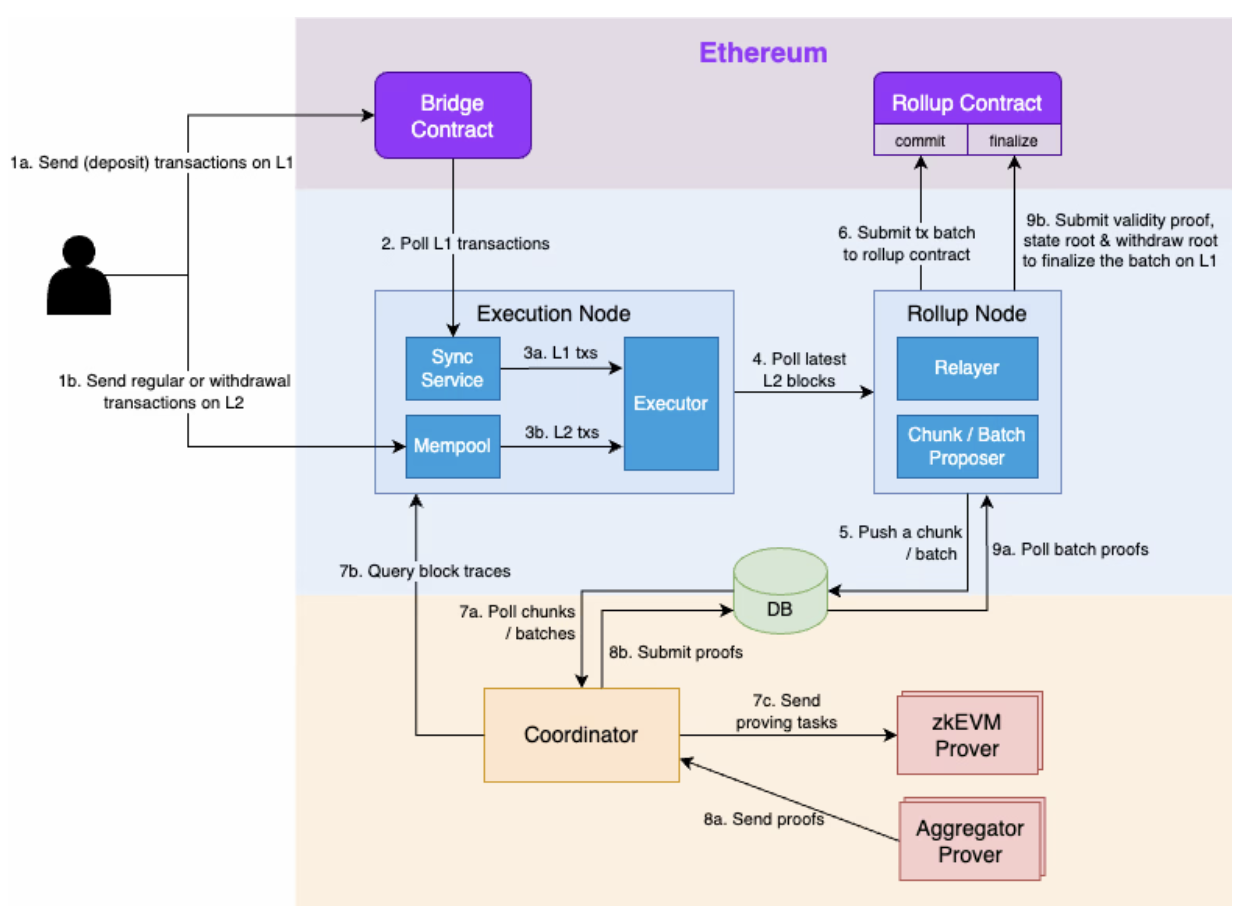
위 그림은 scroll의 작업 흐름이다. Sequencer의 실행 노드는 세가지 모듈이 포함되어 있으며, 각 기능은 아래와 같다.
- Sync service
- L1의 브리지 컨트랙트에서 발행되는 이벤트를 subscribe
- L1 inbox에 새롭게 추가된 메시지가 감지되면
L1MessageTx를 생성하여 로컬 L1 트랜잭션 큐에 추가
- Mempool
- L2 sequencer에 사용자로부터 직접 제출된 tx를 수집
- Executor
- Sync service가 추가한 L1 tx 큐와 mempool에 추가된 L2 tx를 모두 가져와서 새로운 L2 블록을 구성
Sequencer의 롤업 노드도 세가지 모듈이 포함되어 있으며 각 기능은 아래와 같다.
- Relayer
- DA및 finality를 위해 롤업 컨트랙트에 커밋 tx를 제출
- Chunk proposer 및 Batch proposer
- Transaction batching에서의 일괄 처리 과정 (transactions -> blocks -> chucks -> batch)에 따라 새로운 chunk와 batch를 제안
각 모듈들은 위와 같은 기능을 수행하며, 롤업 프로세스가 어떻게 진행되는지 확인해 본다. 아래 프로세스는 그림의 프로세스와 같이 비교해서 보면 좋을것 같다.
1. Transaction execution
- 사용자는 L1 브리지 컨트랙트나 L2 sequencer에 tx를 제출
- L2 sequencer는 sync service에서 새롭게 추가된 L1 tx를 가져옴
- L2 sequencer는 L1 tx queue와 L2 mempool의 tx를 처리하여 L2 블록을 구성
2. Batching 및 데이터 커밋
- 롤업 노드는 최신 L2 블록을 모니터링하고 tx 데이터를 가져옴
- Transaction batching의 제약조건이 충족되면 롤업노드는 새 청크/배치를 제안하고 DB에 기록, 충족되지 않으면 롤업 노드는 추가되는 블록이나 청크를 기다림
- 새 배치가 생성되면 relayer는 배치의 트랜잭션 데이터를 수집하고 DA를 위해 롤업 컨트랙트에 커밋 tx를 제출
3. Proof generation 및 finalization
- Coordinator가 DB에서 새 청크 및 배치를 가져오면(polling) 아래를 수행
- 새로운 청크가 생성되면 coordinator는 L2 sequencer에서 이 청크에 있는 모든 블록을 쿼리한 다음 청크 증명 작업을 무작위로 선택된 zkEVM prover에게 보냄
- 새로운 배치가 생성되면 coordinator는 DB에서 배치에 있는 모든 청크의 증명을 수집하고 배치 증명 작업을 무작위로 선택된 aggregator prover에게 보냄
- Coordinator는 prover로 부터 청크 또는 배치 증명을 받으면 증명을 DB에 기록
- 롤업 릴레이어가 DB에서 새로운 배치 증명을 폴링하면 롤업 컨트랙트에 tx finality를 제출하여 증명을 확인
정리
Option 1은 zk rollup 환경에서 솔리디티를 그대로 해석할 수 있는 런타임 도구를 개발함으로써 구현한다.
모든 opcode를 회로(circuit)에 구현하는 것은 어렵지만 scroll은 EVM을 미러링하도록 구현되기 때문에 현재 EVM과 연관되어 있는 도구들을 명확히 지원할 수 있다는 것에서 큰 장점을 얻는다. 이론상 모든 EVM opcode를 지원할 수 있으나, 현재 "모든" opcode를 지원하지는 못한다.
하지만 EVM의 구조가 단순한것도 아니라서 모든 opcode를 회로로 구현하는 것은 굉장히 힘든 작업이며, EVM을 직접 미러링 할 시 많은 오버헤드가 발생할 수 밖에 없는데, 이는 체인이 엄청난 오버헤드를 직접 수행함으로써 퍼포먼스 측면에서 많이 뒤쳐질 수 있다. 최종 목적은 EVM과 완전히 똑같은 작업을 수행할 수 있도록 만드는 것이기 때문에 확장성을 포기하더라도 호환성을 챙기는 방향으로 개발이 진행된다.
Option2. Custom VM + Opcode support

위 그림의 3번째가 option 2의 대표적인 예로써, Polygon zkEVM이 이 구현방식에 속한다. 앞선 방식과 유사하나, polygon zkEVM의 런타임인 zkExecutor는 EVM 해석(interpretation)을 최적화하기 위해 EVM opcode가 아닌 플랫폼 맞춤형인 zkASM opcode를 실행한다. 이는 EVM을 직접 증명하는 것보다 제약 조건들의 수가 감소하는 결과를 얻게될 수 있다.
zkEVM의 대략적인 구조와 데이터 교환 등에 대한 내용은 polygon zkEVM글에 정리해 놓았다.
정리
Option 2는 커스텀 VM을 개발하고, 솔리디티 opcode를 직접 해석할 수 있도록 대응되는 커스텀 VM용 opcode로 매핑함으로써 구현한다.
위 방식보다 EVM을 직접 증명하는것보다는 오버헤드가 줄어들고, 대부분의 solidity역시 실행이 가능하다. Polygon zkEVM은 또한 기존의 이더리움 사용 툴들을 "100%" 지원하기 위해 노력한다고 했기 떄문에, 같은 EVM JSONRPC가 지원이 되면 기존 개발자들이 사용하던 여러 도구들을 수정/변환 없이 사용할 수 있게 된다. 하지만 커스텀으로 VM을 사용하였기 때문에 L1의 애플리케이션과 도구들이 일부 비호환성이 생길 수 있다.
Option 3. Custom VM + Transpiler
마지막으로 그림의 첫번째, 두번째인 StarkWare의 StarkNet과 zkSync Era가 3번째 구현방식의 대표적인 예이다.
StarkNet은 스마트 컨트랙트 롤업을 위하여 자체 저수준 언어 Cairo를 개발, 이를 사용하여 커스텀 스마트 컨트랙트 VM(Cairo VM)을 실행하도록 만들었다. 또한 솔리디티 코드를 Cairo VM 바이트코드로 변환하도록 하는 Warp transpiler를 개발하여 지원한다.
zkSync Era도 Cairo와 유사하게 Zinc언어를 만들었고, 또한 자체 커스텀 VM(SyncVM)을 개발하였다. 솔리디티에서 EVM 버전 바이트코드로 컴파일 할 수 있는 Yul언어를 통하거나, 자체 언어 Zinc를 LLVM-IR로 컴파일 하기 위한 특수 컴파일러를 구축하여 자신들의 커스텀 VM에 적용할 수 있도록 만들었다. (아래 그림 참조)

정리
Option 3는 커스텀 VM을 개발하고, 해당 VM이 해석할 수 있는 언어를 새로 만들거나, 솔리디티를 해당 언어로 번역하는 해석기를 지원함으로써 구현한다. 역시나 대부분의 솔리디티는 실행가능하며 퍼포먼스 측면에서도 나쁘지 않은 결과를 보인다고 한다.
하지만 각각의 프로젝트에서도 단점이 존재하는데, StarkNet은 이더리움 컴포넌트와 호환성을 목표로 개발하지 않았기 때문에 자체 클라이언트 API, javascript library, wallet 시스템을 운영하여 JSON RPC 지원 가능성이 떨어진다. 또한 Warp에서도 일부 솔리디티 기능을 지원하지 않는 것도 존재한다고 한다. zkSync Era의 경우 StarkNet보다는 이더리움과 조금 더 호환이 가능하다고는 하나 현재는 솔리디티 0.8.X 버전만 지원된다고 한다.
Conclusion
해당 글에서 확인할 수 있는 zkEVM 구현 방안은 크게 3가지였다. 각 옵션의 정리에서도 어떻게 구현하는지에 대해 나열했지만 마지막으로 짧게 정리한다.
| 구분 | 솔리디티 | 미들웨어 | VM |
|---|---|---|---|
| 옵션1 | 그대로 사용 | - | zkEVM 런타임 구축 |
| 옵션2 | 그대로 사용 | 바이트코드(opcode) 매핑 미들웨어 | 커스텀 VM 구축 |
| 옵션3 | 그대로 사용(or 자체언어) | 언어해석기 및 컴파일러 | 커스텀 VM 구축 |
각자 구현 방식은 장단점이 존재한다. 아래 그림은 zkEVM 유형과 그 장단점을 게시한 그래프이다.

요약하자면, Type1에 가까울 수록 이더리움과 완벽하게 호환되며, Type4에 가까울 수록 구축이 쉽고 확장성이 높은 것이 특징이다. 분류하는 기준에 따라 다르겠지만 option 1은 Type1, option 2는 type 2-3, option 3는 type 3-4정도로 분류할 수 있을것이다.
zk rollup을 사용하는 것은, 그 기술을 블록체인 확장성에 적용시키는 것 뿐만 아니라 기존의 시스템과 얼마나 잘 호환되도록 개발하는 것이 중요 관점이라 생각하며, EVM 호환성도 그 중 하나일 것이다. 새로 개발되는 플랫폼들의 아이디어와 기술을 보며 인사이트를 얻고 개발 시 접목 시키는 것이 중요할 것 같다.
참고
https://www.immutable.com/blog/ground-up-guide-zkevm-evm-compatibility-rollups
https://docs.scroll.io/en/technology/
https://vitalik.ca/general/2022/08/04/zkevm.html?ref=blog.thirdweb.com
'Blockchain > Roll up' 카테고리의 다른 글
| ZK rollup - 4. zk-SNARK의 Circuit & QAP (0) | 2023.09.21 |
|---|---|
| ZK rollup - 2. ZKP (0) | 2023.06.15 |
| ZK rollup - 1. 목적/library (0) | 2023.06.15 |
| Rollup의 개념과 특성 (0) | 2023.06.14 |